微分算法
前言
我们在接触深度学习框架 pytorch 的时候,经常会听到 “自动微分” 这个词,以及他相较于传统微分算法的种种优点,那什么是微分算法,有哪些微分算法,和我们大学数学中学的微积分有什么关系与区别。这几个问题我将在下面一一解答。
我们在接触深度学习框架 pytorch 的时候,经常会听到 “自动微分” 这个词,以及他相较于传统微分算法的种种优点,那什么是微分算法,有哪些微分算法,和我们大学数学中学的微积分有什么关系与区别。这几个问题我将在下面一一解答。
大学数学已经全部还给老师了,现在由于需要接触机器学习,其中不乏向量、矩阵、梯度的相关概念,然后各种求导公式看的云里雾里。为了彻底解决这方面的困惑,我决定把关于机器学习中各种和导数相关的概念都整理出来,以便自己的理解以及后续的查阅参考。
消除偏序关系 离散特征(如颜色:红、绿、蓝)的原始数值编码(如红 = 1、绿 = 2、蓝 = 3)会隐含不存在的 “偏序关系”(即算法可能误认为 “红 < 绿 < 蓝”)。而 One-Hot 编码通过独热向量(如红 =[1,0,0]、绿 =[0,1,0]、蓝 =[0,0,1])让每个类别独立且平等,避免算法误判。
等距性 One-Hot 编码后,任意两个类别在向量空间中的距离是相等的(如红与绿的距离 = 红与蓝的距离 =√2)。这保证了算法不会因编码方式对某些类别产生偏好。
兼容连续特征的处理方法 One-Hot 编码将离散特征转换为多维的二元向量后,每一维都可以视为连续值(0 或 1),从而可以像连续特征一样进行归一化(如缩放到 [-1,1] 或标准化为均值为 0、方差为 1)。
解释 “One-Hot 编码后,每一维可视为连续值,并可归一化” 1. One-Hot 编码的结果是二元向量 One-Hot 编码将离散的类别特征(如 “颜色:红、绿、蓝”)转换为多维的二元向量(仅含 0 或 1)。例如:
红 → [1, 0, 0]
绿 → [0, 1, 0]
蓝 → [0, 0, 1]
每个向量的维度数等于类别总数,且只有一个位置是 1(表示当前类别),其余为 0。
数值性质:0 和 1 是实数,可以参与连续值的数学运算(如加减、乘除、求均值等)。
算法兼容性:许多机器学习算法(如神经网络、回归模型)默认输入是连续值。将 One-Hot 向量视为连续值后,可以直接输入这些模型,无需特殊处理。
注意:严格来说,One-Hot 编码是离散的,但因其数值特性,实践中常按连续值处理。

word2vec 工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系。word2vec 工具包含两个模型,即跳元模型(skip-gram) (Mikolov et al., 2013) 和连续词袋(CBOW) (Mikolov et al., 2013)。对于在语义上有意义的表示,它们的训练依赖于条件概率,条件概率可以被看作使用语料库中一些词来预测另一些单词。由于是不带标签的数据,因此跳元模型和连续词袋都是自监督模型。
https://blog.csdn.net/bitcarmanlee/article/details/82291968
https://martinlwx.github.io/zh-cn/the-bpe-tokenizer/
在前面,我已经动手复现了 transformer 模型的整体架构,对其中的每一个模块都有了比较好的了解。但是我对现在主流的一些大模型的结构还不是很了解,之前搭建的 transformer 也只有模型结构,并没有和模型的具体任务进行关联。所以这次我根据 datawhale 的happy-llm 教程,来走一遍从模型搭建到 tokenizer 训练到模型预训练到 SFT 微调的全流程。
大二下的时候,因为参加了本博贯通计划,有幸进入到浙江大学脑机智能实验室进行类脑计算方向的科研探索。那时候应该也是我初次接触深度学习,对图像分类、cnn 这些概念有了一定认知。记得当时刚进实验室的时候没有任何深度学习相关经验的我就对着李沐老师的动手学深度学习硬啃(加上之前寒假看了几节就放弃的 cs231n)。基本上到了 rnn 这一部分开始进入 nlp 的领域,我就已经看不下去了。在最初的阶段,我总是能听到 transformer 这个圣神的词汇,但是对他的认知一直停留在 attention is all you need 这篇论文的标题,以及 QKV 三个矩阵,至于他们具体是什么,我是一概不知。
到后来随着接触了更多深度学习相关的课程,我对 transformer 的理解也逐步深入,也能和同学谈论 transformer 比 rnn 好的地方、transformer 和 cnn 的联系等等话题,论文也基本上看了三四遍,但是我还从来没有认认真真的一行行的去手搓代码,去感受这个 transformer 的真正魅力。现在暑期实习 offer 尘埃落定,也知道了后面我要做和大语言模型相关的工作,那就趁着这个机会,去揭开 transformer 的神秘面纱!
我发现很多时候第一遍学习一个知识总是觉得很难,感觉自己学不会,因为也不是很急可能自然就放弃了。但后面不断听到和这个知识相关的信息,接触更多的资料,虽然没有很深入钻研,但是时间长了以前看来不可逾越的高墙好像也自然瓦解了。学习 transformer 的过程中这样的体验非常非常真切。
1 | brew install uv |
1 | uv init . #把当前目录初始化为uv项目 |
接下来目录中会出现四个文件
1 | ├── .python-version #python版本 |
https://www.bilibili.com/video/BV1ajJ7zPEa5/?spm_id_from=333.337.search-card.all.click&vd_source=e0fd968bc0588f3366eaafdde70c3c44
需要添加库只需运行命令
1 | uv add <package_name> |
此时 uv 会自动创建.venv 虚拟环境,不需要显式手动激活
有可能遇到下载速度慢的问题,需要更换镜像源
1 | cd ~/.config/uv |
添加如下内容:
1 | [[index]] |
这题考察的是模拟,因为在操作的时候一些链会断开,所以一定要想清楚如何暂存节点,并且本题适合用 dummy 处理,因为 head 没有人指着,和后面的逻辑有所不同
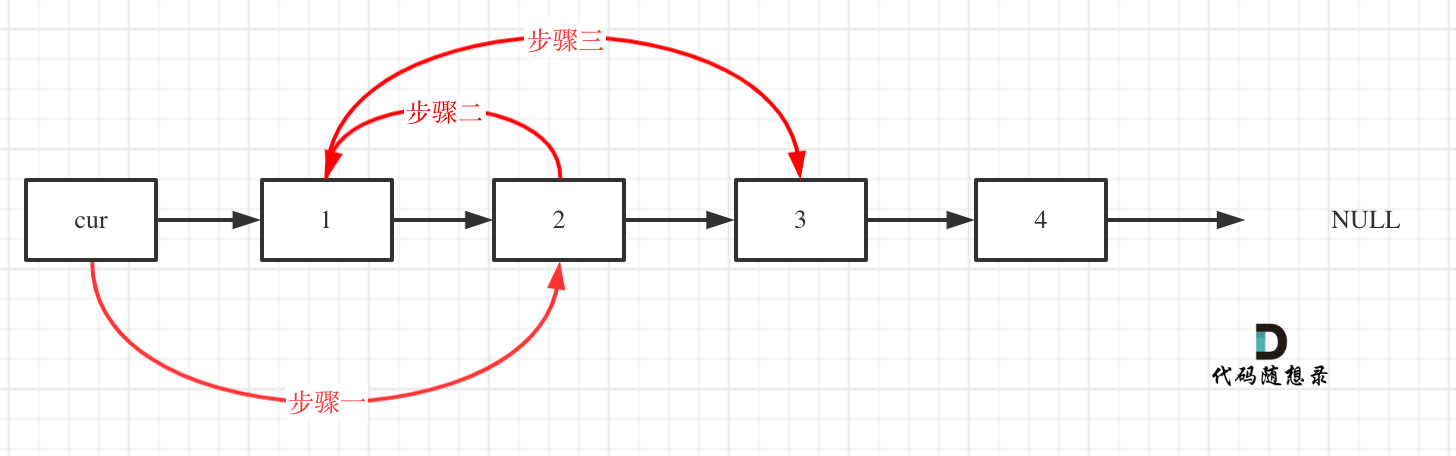
我的解法是步骤 3 - 步骤 2 - 步骤 1,代码如下:
我突然在想为什么新建链表节点必须用 new ListNode (),而不能直接用
ListNode () 呢? 因为链表是动态分配的,new ListNode () 会在堆上分配内存,而
ListNode () 是在栈上分配内存。栈上的变量在函数结束后会被自动销毁,而堆上的变量需要手动释放。
如果用
ListNode (),这个函数结束了会自动销毁变量,造成悬空指针,而链表一般需要全局区调用,所以不能放在栈上。
理解了这个点,这对于内存的堆空间和栈空间应该就更明白了
这是非常基础的链表删除操作,不是很想展开讲了,只需要记住下面几点:
我们在进行 markdown 写作的时候,通常会在文章中插入图片,而 markdown 的图片管理也是很烦人的事情。另外加上 hexo 的一些特性,导致图片本地预览和线上发布不一致,网上也有不少用插件来解决的方法,比如 hexo-asset-img。但是我觉得网上的大多数实践还不够完美,下面我就给出我自己的解决方案。