transformer 复现
前言
大二下的时候,因为参加了本博贯通计划,有幸进入到浙江大学脑机智能实验室进行类脑计算方向的科研探索。那时候应该也是我初次接触深度学习,对图像分类、cnn 这些概念有了一定认知。记得当时刚进实验室的时候没有任何深度学习相关经验的我就对着李沐老师的动手学深度学习硬啃(加上之前寒假看了几节就放弃的 cs231n)。基本上到了 rnn 这一部分开始进入 nlp 的领域,我就已经看不下去了。在最初的阶段,我总是能听到 transformer 这个圣神的词汇,但是对他的认知一直停留在 attention is all you need 这篇论文的标题,以及 QKV 三个矩阵,至于他们具体是什么,我是一概不知。
到后来随着接触了更多深度学习相关的课程,我对 transformer 的理解也逐步深入,也能和同学谈论 transformer 比 rnn 好的地方、transformer 和 cnn 的联系等等话题,论文也基本上看了三四遍,但是我还从来没有认认真真的一行行的去手搓代码,去感受这个 transformer 的真正魅力。现在暑期实习 offer 尘埃落定,也知道了后面我要做和大语言模型相关的工作,那就趁着这个机会,去揭开 transformer 的神秘面纱!
我发现很多时候第一遍学习一个知识总是觉得很难,感觉自己学不会,因为也不是很急可能自然就放弃了。但后面不断听到和这个知识相关的信息,接触更多的资料,虽然没有很深入钻研,但是时间长了以前看来不可逾越的高墙好像也自然瓦解了。学习 transformer 的过程中这样的体验非常非常真切。
学习资料
视频
首先不 top1 的视频一定就是 3b1b 的这个【官方双语】直观解释注意力机制,Transformer 的核心 | 【深度学习第 6 章】。生动的例子和精妙的动画把复杂的概念讲的太好了!
除了 3b1b 的视频我觉得这个视频从编解码和词嵌入开始,一步一步理解 Transformer,注意力机制 (Attention) 的本质是卷积神经网络 (CNN) 讲的也非常好,up 对于 transformer 的理解远超了网上大部分的人
总框架
由于网上关于整个 transformer 原理的讲解已经非常丰富,而且我只是个小白,就不想对整个框架做过于完整的讲述了。我想先把自己最有感悟最核心的部分的学习过程记录下来。刚刚复现完两天,还热乎着。
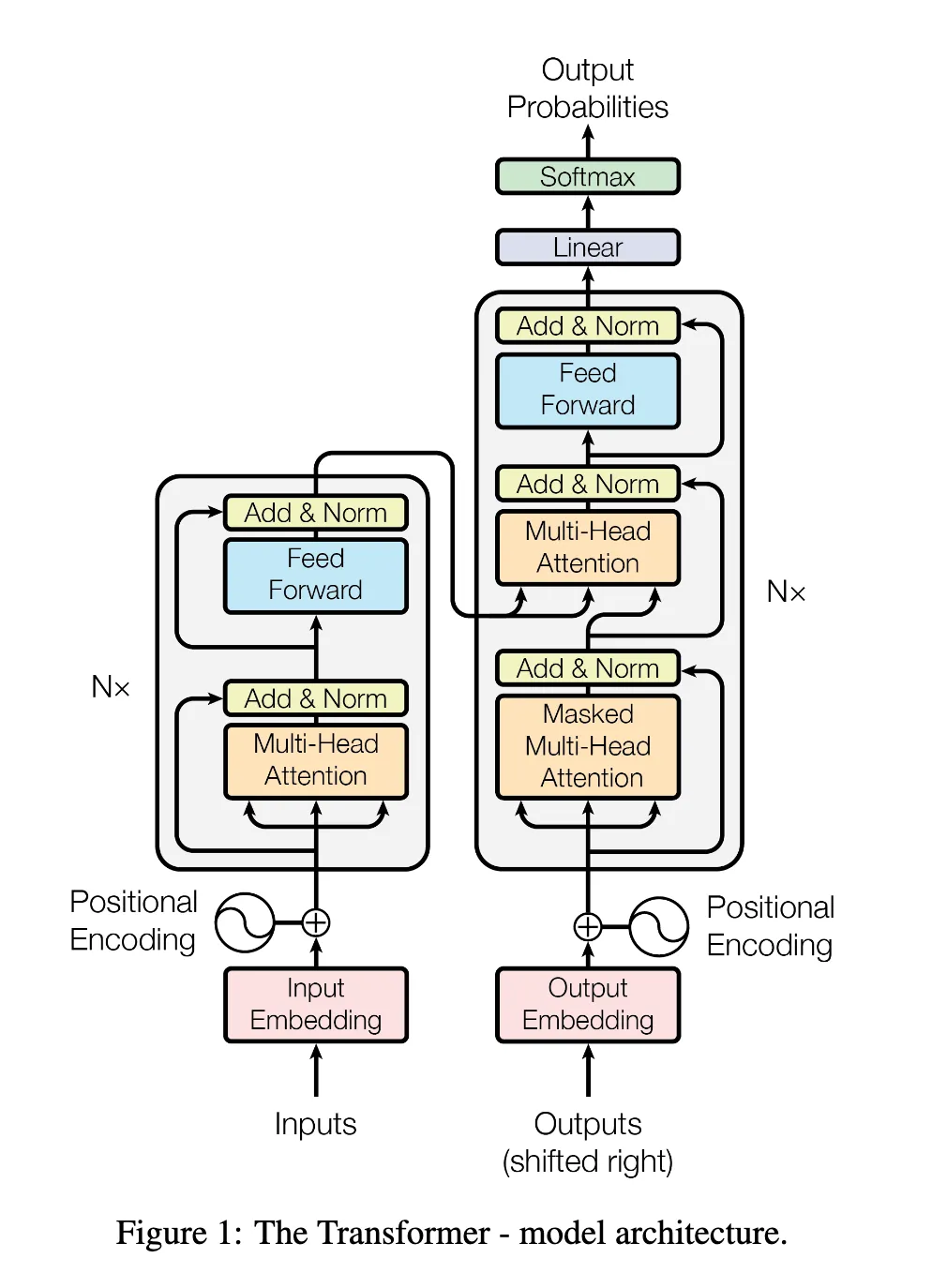 框架图先贴上,后面会不断遇到
框架图先贴上,后面会不断遇到
Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. 这是论文里的原话,重点就在于 q,k,v 这三个东西上
Scaled Dot-Product Attention
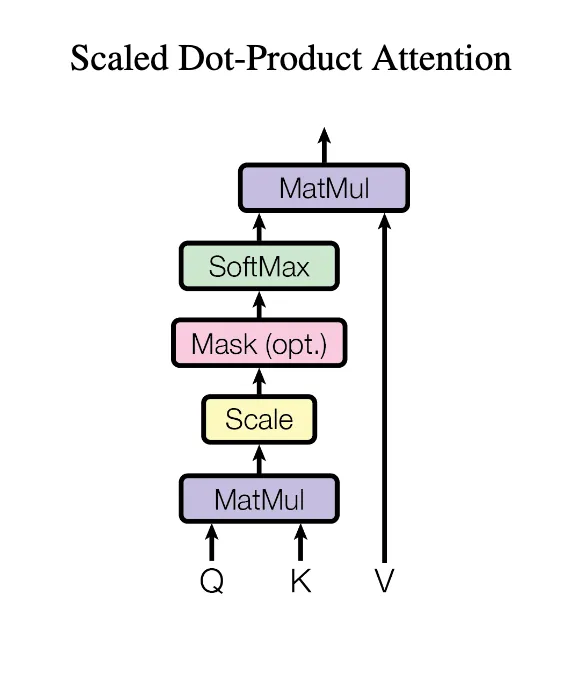 这一部分算是最最核心的部分了,我们先从公式开始:
这一部分算是最最核心的部分了,我们先从公式开始:
矩阵 A 的含义
其中
假设我们有一个简单的句子:“我 爱 深度 学习”
这个句子有 4 个 token,所以矩阵 A 的形状是 (4, 4):
1 | 句子:我 爱 深度 学习 |
矩阵 A 看起来是这样的:
1 | 我 爱 深度 学习 |
矩阵 A 的解读方式 按行理解(这是关键):
- 第 0 行:[a00, a01, a02, a03] 表示 “我” 这个 token 对句子中所有 token(包括自己)的注意力分数
- 第 1 行:[a10, a11, a12, a13] 表示 “爱” 这个 token 对句子中所有 token 的注意力分数
- 第 2 行:[a20, a21, a22, a23] 表示 “深度” 这个 token 对句子中所有 token 的注意力分数
- 第 3 行:[a30, a31, a32, a33] 表示 “学习” 这个 token 对句子中所有 token 的注意力分数
具体数值示例 假设经过计算,矩阵 A 的数值如下(这些是假设的分数):
1 | 我 爱 深度 学习 |
解读:
- “我” 主要关注自己(0.8),对其他词关注较少
- “爱” 既关注主语” 我”(0.3),也关注自己(0.4)
- “深度” 主要关注自己(0.6),也会关注” 学习”(0.1)和” 爱”(0.2)
- “学习” 主要关注自己(0.55),也会关注” 深度”(0.3)
关键理解
- 对角线元素:通常比较大,因为每个词对自己的注意力分数通常最高
- 语义相关性:语义相关的词之间的注意力分数会比较高(如” 深度” 和” 学习”)
- 注意力模式:不同位置的词会形成不同的注意力模式,反映了语言的结构和语义关系
这个矩阵 A 在经过 softmax 归一化后,每一行的和都等于 1,然后用来加权 Value 矩阵 V,最终得到每个位置的输出表示。
A: (seq_len, seq_len) -> softmax -> (seq_len, seq_len) -> V: (seq_len, d_model) -> output: (seq_len, d_model)
Softmax 归一化
首先,对矩阵 A 的每一行进行 softmax 归一化。原始的矩阵 A 经过 softmax 归一化后,假设得到矩阵 A’:(里面的具体数值不一定是 softmax 的正确结果,这里仅仅作为演示)
1 | 我 爱 深度 学习 (行和) |
Value 矩阵 V
假设我们的 Value 矩阵 V 是一个 (seq_len, d_model) 的矩阵,其中 d_model 是 value 的维度。为了简化,假设 d_model = 3:
1 | 我 [1.0, 0.5, 0.2] |
对于模型的输入 token 序列 “我 爱 深度 学习”,进入 encoder 前已经进行了词嵌入 embedding,将其转化为 (seq_len, d_model) 的输入矩阵 X。d_model 可以理解为词向量的维度。
接下来 X 就进入了我们的 Attention 模块,被转化为 QKV 三个矩阵。具体的转化过程是通过线性变换实现的,即
这里的
我们把 V 矩阵可以暂时理解为每个 token 固有的语义特征,不包括上下文信息。比如苹果这个 token(词)的 V 矩阵可能是 [0.8, 0.6, 0.1],你可以把这三个维度分别理解为水果,甜,电子产品。如果出现在上下文” 我爱吃苹果 “中,那他的词义不太会变化,V 矩阵变化的比较小,比如变成 [0.7, 0.8, 0.05];但如果出现在上下文” 我爱用苹果手机 “中,那他的词义就会发生变化,变成了电子产品的意思,V 矩阵就会变成 [0.1, 0.2, 0.9],和之前差别很大。所以 V 矩阵是和上下文相关的。
这里说到的” V 矩阵变化”,指的就是
计算输出
输出矩阵
我把他们放在一起,这样就会很好理解了:
1 | A': 我 爱 深度 学习 V: |
接下来的矩阵乘法就会非常的直观,A’的每一行都和 V 矩阵的每一列相乘,等于是对 V 矩阵的每一列进行加权求和。比如第四行的计算过程如下:
1 | O[3][:] = 0.05 * [1.0, 0.5, 0.2] + 0.1 * [0.8, 1.2, 0.4] + 0.3 * [0.3, 0.9, 1.5] + 0.55 * [0.6, 0.7, 1.1] |
上式的直观理解如下: A’矩阵的第四行所讲的是” 学习 “这个 token 对所有 token 的注意力分数,V 矩阵的第四行是” 学习 “这个 token 的固有语义特征。通过 A’和 V 的矩阵乘法,我们希望更新 V 矩阵中第四行” 学习 “的语义特征,使其更符合上下文的语义。然后可以发现,由于学习和深度的分数比较高(0.3),所以最后计算得到的 “学习” 的最终语义特在保留原有特征的基础上,同时较多融入了 “深度” 的语义特征。
最终的结果
1 | 输出 O (4×3): |
- 加权融合:每个位置的输出都是所有位置 value 向量的加权平均,权重就是注意力分数
- 信息聚合:
- “我” 的输出主要来自自己的 value(权重 0.7)
- “深度” 的输出更多融合了自己(权重 0.6)和相关词的信息
- “学习” 的输出主要来自自己(权重 0.55)和” 深度”(权重 0.3)
- 上下文表示:最终每个位置的输出不再是独立的词向量,而是融合了整个句子上下文信息的表示
我觉得这里的矩阵乘法有两种理解:
- 看成 A’的每一行和 V 矩阵的每一列相乘,等于对 V 矩阵的每一列进行加权求和,即语义的每一维特征都被加权求和考虑上下文
- 看成 A’的每一行和 V 矩阵整个相乘,直接打包所有特征维度,得到所有 token 进行加权求和
这两种理解区别应该仅仅是整体和部分的区别
务必要看懂上面的例子!!! 这对于充分理解为什么 attention 机制能够融合上下文信息是非常重要的! 关键词:注意力分数、固有特征、加权求和
代码实现
1 | def scaled_dot_product_attention(self, Q, K, V, mask=None): |
这一部分是接下来马上要讲的 multi-head attention 的一个部分,光看这段代码可能会感觉少了点什么东西,不过不用急。首先先在这段代码里面找一些熟悉的东西: - Q, K, V - attention scores - softmax - attention_probs
接下来请你把每个矩阵的形状都写出来,看一下是怎么变化的,是否和前面分析的一致。
你可能对这里的 mask 不太理解,不要紧,现在不重要,而且我也不大理解(狗头),后面会讲到的。现在只需要知道它是一个可选参数,用来屏蔽掉一些不需要关注的部分。
Multi-Head Attention
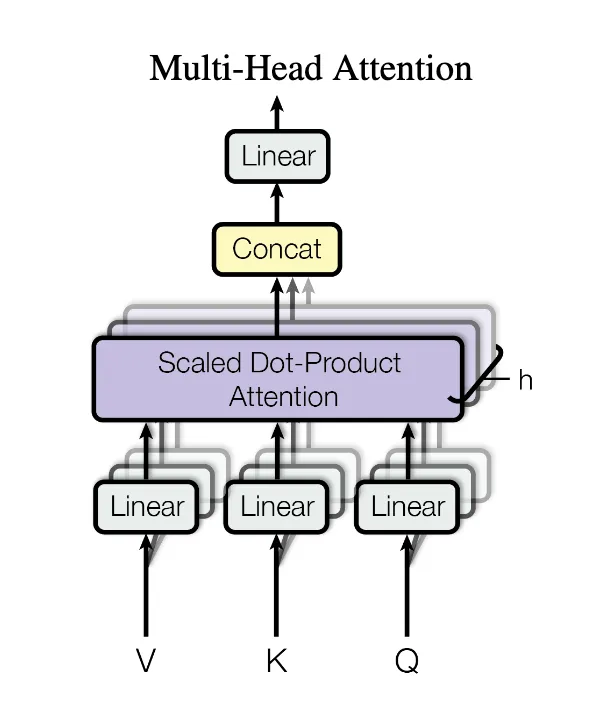
单一的 Self-Attention 机制可能只捕捉到一种类型的依赖关系。语言是复杂的,一个词与其他词的关系可能有多种模式(例如,一个词可能同时与语法相关的词和语义相关的词有强关联)。
通过并行地执行多个 Self-Attention 操作(称为 “头”),每个头可以学习关注序列中不同方面或不同子空间的信息(例如,一个头关注句法关系,另一个头关注指代关系,等等)。
其实多头和 cnn 中的多个卷积核很像,是为了捕捉不同的特征模式(比如一个卷积核捕捉边缘特征,另一个捕捉纹理特征)。所有 C_out 个卷积核计算出的 C_out 个特征图